

在資料庫中當資料量變大時,Index 能幫助加速查詢。但剛接觸資料庫的時候,可能會有個疑問:「如果 Index 能讓搜尋變快,那是不是應該對所有欄位都加上 Index?」
實際上 Index 提升查詢速度的原理,是透過「空間換取時間」的方式來達成。這部分我們會在 Day 3 (B-Tree) 詳細說明。
在這篇文章,我們先來看看 PostgreSQL 是不是真的使用了 Index 來加速查詢,可以新增一個測試用的 users table,觀察一下在什麼情況 PostgreSQL 會使用 Index。
1. 建立 users
CREATE TABLE users (
id INTEGER,
display_name VARCHAR,
email VARCHAR
);
2. 塞入測試資料
使用 Python script 先塞入 100 筆測試資料:
import psycopg2
from faker import Faker
fake = Faker()
conn = psycopg2.connect(dbname="", user="", password="") # 換成自己的 db
cur = conn.cursor()
insert_query = "INSERT INTO users (id, display_name, email) VALUES (%s, %s, %s)"
data = [(i, fake.name(), fake.email()) for i in range(1, 101)]
cur.executemany(insert_query, data)
conn.commit()
cur.close()
conn.close()
這樣我們就有 100 筆隨機產生的使用者資料了。
3. 觀察 SQL
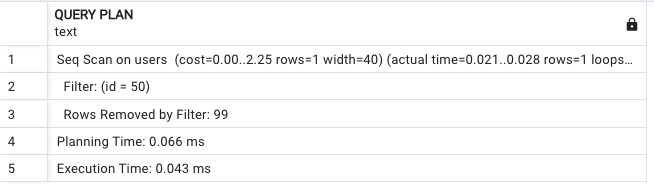
在 PostgreSQL 中,可以使用 EXPLAIN ANALYZE 來觀察 SQL 的效能。我們先執行以下 SQL,查看資料庫搜尋 id 是否會使用 Index:
EXPLAIN ANALYZE SELECT * FROM users WHERE id = 50;
在這邊可以看到關鍵字 Sequential Scan,搜尋了一下這個詞,發現他表示資料庫一筆一筆掃描資料表,來尋找符合條件的資料。
4. 加上 Index
接著,我們把 id 建立 Index:
CREATE INDEX users_id_index ON users (id);
再執行相同的查詢:
EXPLAIN ANALYZE SELECT * FROM users WHERE id = 50;
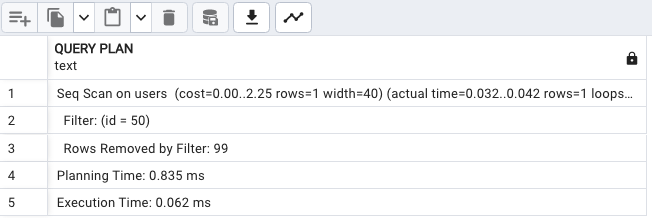
這時候會發現 query plan 仍然是 Sequential Scan。那說好的 index 呢?怎麼沒有出現?
5. 增加資料量,觀察 Index 變化
我們再執行 script 匯入 200 筆資料:
data = [(i, fake.name(), fake.email()) for i in range(101, 301)]
cur.executemany(insert_query, data)
conn.commit()
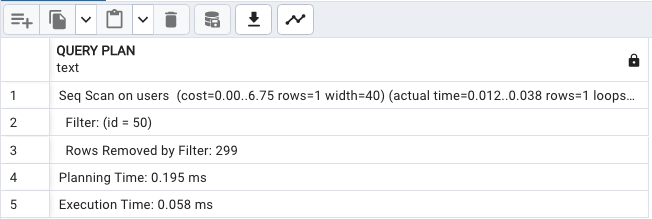
這時候再執行 EXPLAIN ANALYZE ,還是沒有 index 關鍵字出現,那再匯入 200 筆資料。
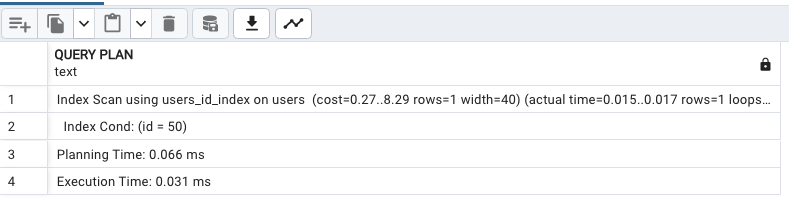
data = [(i, fake.name(), fake.email()) for i in range(301, 501)]
cur.executemany(insert_query, data)
conn.commit()
這時候再執行 EXPLAIN ANALYZE ,Query Plan 變成 Index Scan 了!
如果好奇的話,可以把 index 刪掉試試:
DROP INDEX users_id_index;
再次執行 EXPLAIN ANALYZE,會發現查詢又回到了 Sequential Scan。
回顧剛剛的測試,當資料量少於 300 筆時,PostgreSQL 並沒有使用 Index,而是選擇 Sequential Scan。這是因為 PostgreSQL 會根據查詢成本(Query Cost)動態決定是否使用 Index。根據官方文件:
Once an index is created, no further intervention is required: the system will update the index when the table is modified, and it will use the index in queries when it thinks doing so would be more efficient than a sequential table scan.
簡單來說,當資料量較少時,直接掃描整張表(Sequential Scan)可能比使用 Index 還快,因此 PostgreSQL 會選擇不使用 Index。隨著資料量增加,查詢 Index 變得比全表掃描更有效率,這時候 Index Scan 就會出現了。
所以這是我們實驗後的結果,當資料到達 500 筆時,資料庫判斷使用 Index 會比較快。
| Rows | Time |
|---|---|
| 100 | 0.062ms (Seq scan) |
| 300 | 0.058ms (Seq scan) |
| 500 | 0.031ms (Index scan) |
在接下來的文章中,我們會常常使用到 EXPLAIN ANALYZE 這個語法來觀察 SQL 執行的速度。 如果只單用 EXPLAIN 的話,他不會實際執行 SQL,而是用預估的方式顯示要使用的 Query Plan 和所需時間。
使用 EXPLAIN ANALYZE 的話,會實際執行 SQL,並且會有更詳細的執行時間資訊。但如果在實務上想要觀察 INSERT / UPDATE / DELETE 的語法,就要小心地使用 EXPLAIN ANALYZE ,因為他會實際更改到資料喔~
EXPLAIN ANALYZE 來確認查詢是否有使用 Index。https://www.postgresql.org/docs/current/indexes-intro.html
